Stable trading relationships with nearby countries. Basic human rights. A planet capable of sustaining life. What do these three things have in common?
The answer is that they are all impermanent. One moment we have them, the next moment – whoosh! – they’re gone.
Today I decided I would embrace our new age of impermanence insofar as it pertains to my home directory. Specifically, I wondered whether I could configure a Linux installation so that my home directory was mounted in a ramdisk, created afresh each time I rebooted the server.
Why on earth would I want to do something like that?
(Or a fun way to introduce local kids to programming)
A previous employer encouraged me to join the STEM Ambassador program at the end of 2017 (https://www.stem.org.uk/stem-ambassadors) and I willingly joined, wanting to give something back to society. The focus of the program is to send ambassadors into schools and local communities, to act as role models and to demonstrate to young people the benefits and rewards that studying STEM subjects can bring. I approached my local primary school (at the time my daughter was a pupil there) about the possibility of setting up an after-school computing club, and they jumped at the chance.
I started the club unsure what to expect, but with a lot of hope and some amount of trepidation. I took on groups of 10 or so KS2 pupils, teaching them the basics of loops, events, variables and functions, largely using Scratch (https://scratch.mit.edu/) and an eclectic mix of programmable robots that I’d acquired over the years (I have a few from Wonder Workshop https://www.makewonder.com/robots/ and also a pair of Lego Boost robots https://www.lego.com/en-gb/product/boost-creative-toolbox-17101). Running the club was extremely rewarding. Some of the kids were brilliant, and will no doubt have a great future ahead of them. Others mainly wanted only to drive the robots around – but I figured that as long as they were having fun then their and my time was well spent.
Then, in March 2020, the Covid-19 pandemic hit. Kids were sent home for months, and all clubs were cancelled, with no knowing when they might start up again. The pandemic has obviously been tough for everyone, but one of the hidden effects has been the impact on the education of our children. It will take years, probably, to know exactly what effect two years of lockdown has had on the attainment opportunities and mental heath of young people. Many of them missed out not only on in-person schooling, but also on all the additional extra-curricular opportunities like school visits, and also things like the STEM Ambassador program.
So now, two years and a change of jobs later, I thought it was about time I got myself back in the field, and start up my STEM activities again.
My first opportunity has been to run a “retro games arcade” stall at the school’s summer fair. This involved commandeering a tiny wooden cabin plonked the wrong-way-round on the edge of the school field, next to one of the temporary classrooms. To turn this into a games arcade I needed to black out the windows to make it dark enough inside to see a computer screen, then to run an extension lead out of the window of the classroom, and to quietly steal a few chairs and tables upon which to set up my “arcade consoles”. Blacking out the windows was achieved by covering them up with garden underlay and sticking drawing pins around the edges (much to the detriment of my poor thumbs).
The field and cabin in which I did my STEM Ambassadoring, with the (mostly willing) assistance of my daughter
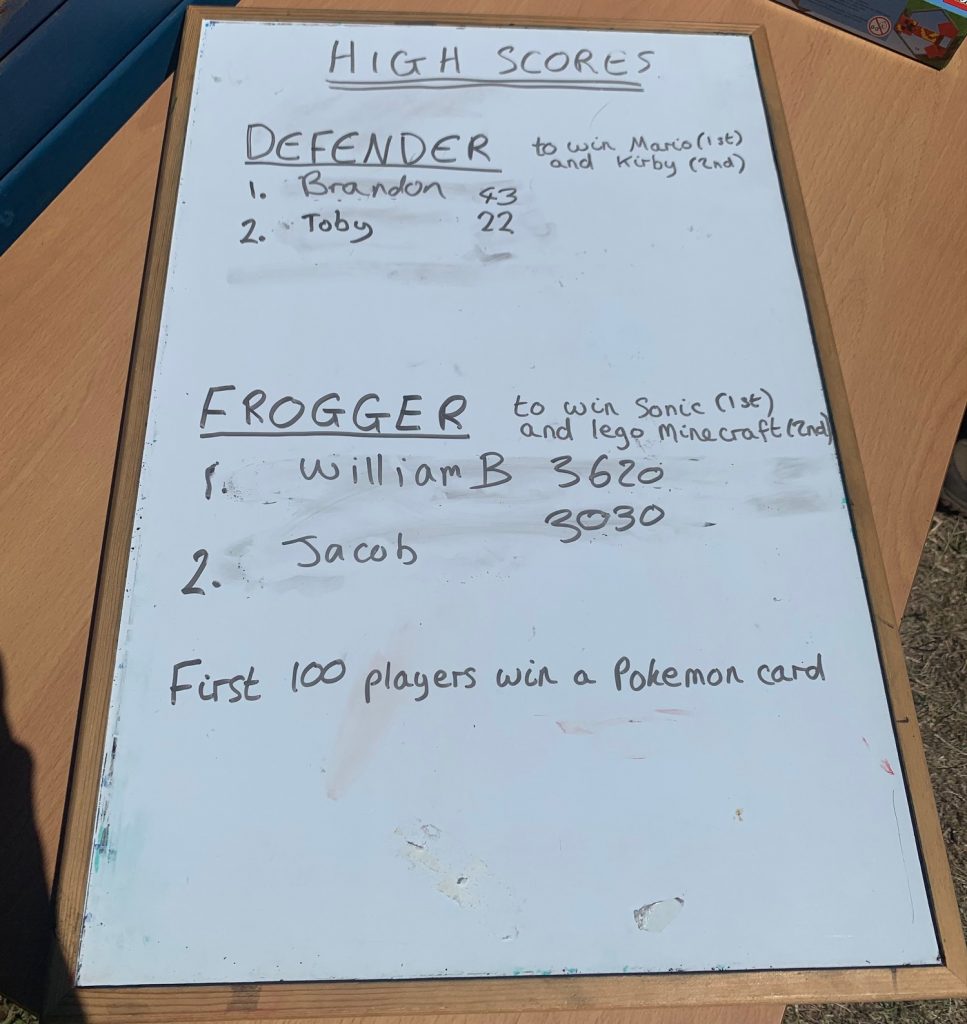
For the arcade machines, I wrote two games in Scratch based around the classic arcade games “Defender” and “Frogger”. I set up two laptops to run these games, covering over all but the arrow keys, trackpad and spacebar with shiny card. My aim was to write games that the students could replicate themselves, if they wished. I wanted games simple enough that a small child could play, but would also be fun for an older child or a parent to play as well. The gameplay should ideally last for 1-4 minutes, and the player should be able to accumulate a high score. As the afternoon progressed I kept track of the highest two scores in each game so that the players with these scores could win a prize at the end of the afternoon.
If you’re interested in seeing these games then you can have a look here:
The two “retro arcade games” I ran at the summer fair.
Of course the afternoon in question was one of the hottest days of the year. I spent 3 hours diving into and out of the tiny sweltering cabin, caught between managing the queue, taking the 50p fee, handing out Pokémon cards to the players (I got a stack of them and gave one out to every player), explaining to the kids how to play the games, and keeping track of the ever-changing high scores. I did have willing help from my daughter (who especially liked taking the money) and my husband (who seemed adept at managing the queue). At some point I managed to eat a burger and grab a drink, but it was a pretty frenetic afternoon.
67 Bricks agreed to give me £50 to pay for prizes. I bought Sonic and Mario soft toys, a Lego Minecraft set, and a large pack of assorted Pokémon cards. I also washed up a Kirby soft toy that I found in my daughter’s “charity shop” pile and added that to the prize pool. Throughout the afternoon I kept track of the top two highest scores in both games, using the incredibly high-tech method of a white-board and dry-wipe marker. The hardest part was figuring out how to spell everyone’s name, and in moving the first-place score to second place every time a high-score was beaten. Oh, and making sure the overly-enthusiastic children didn’t wander off with poor Mario before the official prize giving ceremony.
My high-tech leader board, and some of the prizes on offer for the high scores.
As the afternoon progressed I encountered some kids who aced the games, and actively competed with each other to keep their place at the top of the leader board. Other children struggled to control the game and I had to give them a helping hand (quite literally – I said I would control the cursor keys while they controlled the space bar). And then there was the dad who was determined to win a prize for his child, and kept returning to make sure of his position on the leader board. But eventually the last burger was eaten, the arcade was closed, and the prizes announced. Four children went home happily clutching their prizes and the rest their collection of assorted Pokémon cards.
For the next step in my STEM Ambassador journey, I have agreed to start up the computing club again in September. I’m hoping to teach the children the skills to write their own arcade games in Scratch. Watch this space.
Note, this post is based on a dev forum put together by Chris.
Full-text search is a common feature of systems 67 Bricks build. We want to make it easy for users to find relevant information quickly often through a faceted search function. Understanding user needs and building a top notch user experience is vital. When building faceted search, we generally use either ElasticSearch (or AWS’s OpenSearch) or MarkLogic. Both databases offer very similar feature sets when it comes to search, though one is more targetted towards JSON based documents and the other, XML.
Search can seem magical at first glance and do some amazing things but this can lead to situations where customers (and UX/UI designers) assume the search mecahnism can do more than it can. We frequently find a disconnect between what is desired and what is feasable with search systems.
There are 2 main categories of problems we often see are:
Customers / Designers asking for things that could be done, but often come with nasty performance implications
Features that seem reasonable to ask for at first glance, but once dug into reveal logical problems that make developing the feature near impossible
Faceted Search
Faceted search systems are some of the most common systems we build at 67 Bricks. The user experience typicallly starts with a search box that they enter a number of terms into, hit enter and then be presented with a list of results in some kind of relevancy order. Often there is a count of results displayed alongside a pagination mechanism to iterate through the results (e.g. showing results 1-10 of 12,464). We also show facets, counts for how many results fit into different buckets. All this is handled in a single query that often takes less than 100ms which seems miraculous. Of course, this isn’t magic, full-text search systems use a variety of clever indexes to make searching and computing the facet counts quick.
Lets make a search system for a hypothetical website cottagesearch.com. Our first screen will present the user with some options to select a location, the date range they want to stay and how many guests are coming. We perform the search and show the matching results. How should we display the results and more importantly, how do we show the facets?
Let’s say we did a search for 2 bedroom cottages. We’ve seen wireframes for a number of occassions where the facet count for all bedroom numbers are displayed. So users see the number of results applicable to each bedroom count they would get if they didn’t limit the search to just 2 bedrooms (i.e. there aren’t that many 2 bed options, but look at how many 3 bed options are available). At first glance, this seems like a sensible design, but fundmanetally breaks how search systems work with faceting, they will return counts, but only for the search just done.
We could get around this by doing 2 searches, 1 limited by bedrooms and one that does not to retrieve the facet counts. This may seem like a sensible idea when we have 1 facet, but what do we do when we have more? Do we need to do multiple searches, effectively making an N+1 problem? How to we display numbers? Should the counts for the location facet include the limit of bedrooms or not? As soon as we start exploring additional situations we start to see the challenges the original design presents.
This gets harder when we consider non-exclusionary facets. Let’s say our cottage search system lets you filter by particular features, such as a wood burner, hot tub or dishwasher. Now, if we show counts of non-selected facets, what do these numbers represent? Do they include results that already include the selected facet or not? Here, the logic starts to break down and becomes ever more confusing to the end user and difficult to implement for the developer.
Other Complex Facet Situations
A common question we need to ask with non-exclusionary facets: Is it an AND or an OR search? The answer is very domain dependant, but either way we suggest steering away from facets counts in these situations.
Date ranges provide an interesting problem, some sites will purposefully search outside of the selected range so as to provide results near the selected date range. This may be a useful or annoying depending on what the user expects and is trying to achieve. Some users would want exact matches and would have no interest in results that do not meet the selected date range.
Ordering facets is also a questions that may be overlooked. Do you order lexographically or do you order by descending number of matches? What about names, year ranges or numeric values? Again, a lot of what users expect and would want comes down to the domain being dealt with and the needs of the users.
When users select a new facet, what should the UI do? Should the search immediately rerun and the results and facets update or should there be a manual refresh button the user has to select before the search is updated? An immediate refresh would be slower, but let users narrow down carefully, while a manual update would reduce the number of searches done, but then users may be able to select a number of facets in such a way that no results would be returned.
Hierarchies can also prove tricky. We often see taxonomies being used to inform facets, say subjects with sub categories. How should these be displayed? Again there are many solutions to pick from with different sets of trade-offs.
Advanced Search
Advanced search can often be a bit like a peacocks tail – something that looks impressive, but doesn’t contribute a fair share of value based on how much effort it takes to develop. A lot of designers and product owners love the idea of it but in practice, it can end up being somewhat confusing to use and many end users end up avoiding it.
Boolean builders exist in many systems where the designer of advanced search will insist on allowing users to build up some complex search with lots of boolean AND/OR options, but displaying this to users in a way they can understand is challenging. If a user builds a boolean search such as: GDP AND Argentina OR Brazil do we treat it as (GDP AND Argentina) OR Brazil or should it be interpreted as GDP AND (Argentina OR Brazil). We could include brackets in the builder, but this just further complicates the UI.
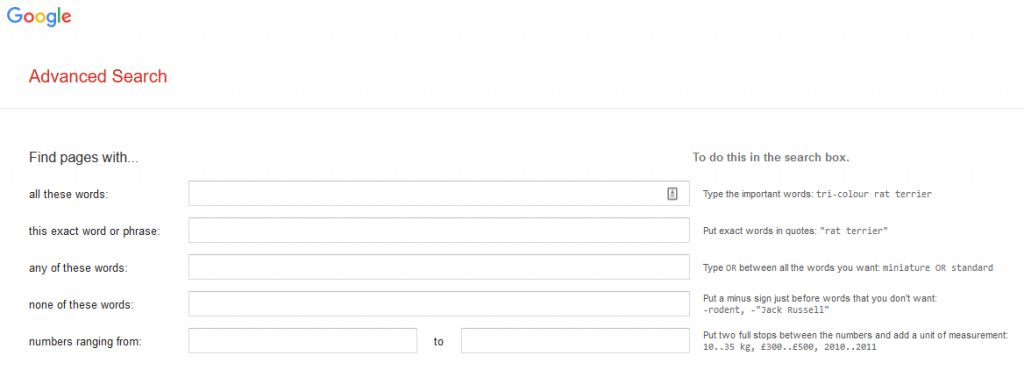
We frequently get bugs and feedback on advanced search, some of this feedback can amount to different users having contradictory opinions on how it should work. We would ask product owners to carefully consider “How many people will use it?” Google has a well build UI for advanced search that does away with the challenges of boolean logic by having separate fields for ANDs ORs and NOTs.
An advanced search facility can introduce additional complexity when combined with facets. If an advances search lets you select some facets before completing the search, does this form part of the string in the search box? We have had mixed results with enabling power users to enter facets into search fields (e.g. bedrooms:3), but this can be tricky, some users can deal with it, but others may prefer a advanced search builder while others will rely on facets post search.
Summary
In conclusion, we have 3 main takeaways
Search is much more complex than it first appears
Facets are not magic, just because you can draw a nice wireframe doesn’t make it feasable to develop
Advanced search can be tricky to get right and even then, only used by a minority of users
We’ve build many different types of search and have experimented with a number of approaches in the past and we offer some tried and tested principles:
Make searches stateless – Don’t add complexity by trying to maintain state between facets changes, simply treat each change as a fresh search. That way URLs can act as a method of persistence and bookmarking common searches.
Have facets only display counts for the current search and do not display counts for other facets once one has been selected within that category.
Only use relevancy as the default ordering mechanism – You may be tempted to allow results to be ordered in different ways, such as published date, but this can cause problems with weakly matching, but recent results appearing first.
Don’t build an advanced search unless you really need to and if you have to, use a Google style interface over a boolean query builder.
Check that search is working as expected – Have domain experts check that searches are returning sensible results and look into using analytics to see if users are having a happy journey through the application (i.e. run a search and then find the right result within the first few hits).
Beware of exhaustive search use cases – As many search mechanisms work on some score based on relevancy to the terms entered, having a search that guarantees a return of everything relevant can be tricky to define and to develop.
When I joined 67 Bricks in January 2021 I knew close to zero about AWS, and not-a-lot about cloud services in general. I had dabbled a bit in Azure in my previous job, and I understood the fundamentals of what “the cloud” was, but I was very aware that I’d have to get up to speed if I wanted to be useful at developing applications on AWS. I joined our team on the EIU project, and on day one I was exposed to discussions about S3 buckets, lambda functions, glue jobs and SNS topics – all things I knew nothing about.
I asked one of the EIU enablement team to give me an overview, and I was introduced to the AWS console and shown some of the key services. Over the next few months I gradually started to get to grips with the basics – I learned how to upload to and download objects from S3, write to and query a DynamoDB table, and search for things in CloudWatch. I was very proud when I wrote my first lambda function, but I still felt like I was winging it.
I was encouraged by our development manager to look into obtaining some AWS certifications. The obvious starting point was Cloud Practitioner (https://aws.amazon.com/certification/certified-cloud-practitioner/?ch=sec&sec=rmg&d=1) which covers the basics of what “the cloud” is, and the applications of core AWS services. The best course I found to prepare for this was one from Amazon themselves https://explore.skillbuilder.aws/learn/course/134/aws-cloud-practitioner-essentials (you might need to sign in to the skill builder to access it, but the course is free). It uses the analogy of a coffee shop to explain the concepts of instances, scaling, load balancing, messaging and queueing, storage, networking etc, in an easy to understand manner. After a lot of procrastinating, and wondering if I was ready, I eventually took the exam in October 2021 and passed it with a respectable score.
The cloud practitioner course covers AWS services in an abstract manner – you learn about the core services without ever having to use them. In fact you could probably pass the course without ever logging into the AWS console. To demonstrate real experience and knowledge of AWS services, I decided that the certification to go for next was Developer Associate (https://aws.amazon.com/certification/certified-developer-associate/?ch=sec&sec=rmg&d=1). AWS doesn’t offer their own course to study for this certification – instead they provide links to numerous white papers, which make for fairly dry reading, and it is not clear exactly what knowledge is and is not required.
After doing a bit of research I decided that this course on Udemy https://www.udemy.com/course/aws-certified-developer-associate-dva-c01/ by Stephane Maarek was the most highly rated. With 32 hours of videos to absorb, this was not a trivial undertaking, but after slotting in a few hours of study either before work or in the evenings, I made it through with two books stuffed with notes.
The Developer Associate certification requires you to understand at a fairly deep level how the AWS compute, data, storage, messaging, monitoring and deployment services work, and also to understand architectural best practices, the AWS shared responsibility model, and application lifecycle management. A typical exam question for Developer Associate might ask you to calculate how many read-capacity-units or write-capacity-units a DynamoDB table consumes under various circumstances. Another one might test your understanding of how many EC2 instances a particular auto-scaling policy would add or remove. Another question might require you to understand what lambda concurrency limits are for.
But what next? The knowledge I’d gained up until this point had given me real practical skills, and a deeper knowledge of how the various AWS services connect together. For example, it was no longer a mystery how lambda functions could be triggered by SNS topics or messages from an SQS queue, and could then call another API perhaps hosted on EC2 to initiate some other process. And I could understand how to utilise infrastructure-as-code (e.g. CloudFormation or CDK) along with services like CodePipeline and CodeDeploy, to automate build processes. But I wanted a greater understanding of the “bigger picture”, and so next I chose to go for the Solutions Architect Associate certification (https://aws.amazon.com/certification/certified-solutions-architect-associate/?ch=sec&sec=rmg&d=1).
The Solutions Architect Associate exam typically presents a scenario and then asks you to choose which option provides the best solution. One option is usually wrong, but there could be more than one solution which would work – but you have to scrutinise the question to see which one best meets the requirements of the scenario. Are they asking for the cheapest solution? Or the fastest? Or the most fault tolerant? (Look for clues like “must be highly available” – and so the correct answer will probably involve multi-AZ deployments). Is any down-time acceptable? Is data required in real time, or is a delay acceptable? (E.g. do we choose Kinesis or SQS?) If a customer is migrating to the cloud are there time constraints, and how much data is there to migrate? (E.g. it can take a month or two to set up a Direct Connect connection, but you could have a Snowmobile in a week. A VPN might work but there are limits to the data transfer rates).
Again, I chose Stephane Maarek’s course on Udemy (https://www.udemy.com/course/aws-certified-solutions-architect-associate-saa-c02/) – his study materials are clear and he also notes which sections are duplicates of those in the developer associate course. I again used Jon Bonzo’s practice exams (https://www.udemy.com/course/aws-certified-solutions-architect-associate-amazon-practice-exams-saa-c03/). There is a fairly hard-core section on VPC, which is something I struggled with. Stephane presents a spaghetti-like diagram showing the relationship between VPCs, public and private subnets, internet gateways, NAT gateways, security groups, route tables, on-premise set-ups, VPC endpoints, transit gateways, direct connections, VPC peering connections etc – and says “by the end of this section you’ll know what all of this means”. He was right, but as someone with limited networking experience and knowledge, I found it pretty tough.
I sat the exam in April 2022, a day before I figured out that the cough and fatigue I’d developed was actually Covid. I passed the exam respectably again, and then collapsed into bed for a few days to recover.
At this point it’s probably worth mentioning how the exam process works. If you like, you can book an exam in an approved test centre. However, I chose to go with the “online proctored” exams hosted by Pearson Vue. You book an exam slot – generally plenty are available at all times of the day and night, and you can usually find a slot within the next day or two that suits. For the exam you need to be sitting at a clear table with nothing within arms reach. Not even a tissue or a glass of water. You need to run some Pearson software on your laptop that checks no other processes are running (so turn off slack, email, shut down your docker containers etc etc), and then launches their exam platform. You will be asked to present photo ID, and then show the proctor your testing environment. They will want to see your chair and table from all angles, and will want to see your arms to make sure you’re not wearing a watch or have anything hiding up your sleeves. You need your mobile phone in the room, but out of reach, in case they need to call you. And you also need to make sure you are undisturbed in the room for the duration of the exam (which is typically 2-3 hours).
This last point was challenging for me. My home-office is not suitable – being far to crammed with potential cheat material, and I also share it with my husband. The only suitable place is my dining table, in the very open-plan ground floor of my house. Finding a time when I can have the ground-floor to myself for 2-3 hours means scheduling the exam for around 7AM in the morning on a day when the kids are not at school. I ended up putting “do not disturb” signs on the door and issuing dire warnings to everyone that they mustn’t come downstairs until I’d given them the all-clear. Anyone wandering sleepily through the room on a quest for coffee could result in the exam proctor dropping my connection and disqualifying me from the exam. Fortunately, all was well and all the exams I’ve sat so far were carried out without incident.
After obtaining the Solutions Architect Associate certification I thought about taking a break. But then I took a look at the requirements for SysOps Administrator Associate (https://aws.amazon.com/certification/certified-sysops-admin-associate/?ch=sec&sec=rmg&d=1) and realised that I’d already covered about two-thirds of the required material. Now SysOps is not something I have a love for. I have a deep respect for people who understand deployments and pipelines and infrastructure. The Enablement team at the EIU, who I work closely with, are miracle workers who regularly perform magic to get things up and running. The idea that I could learn some of that wizardry seemed far-fetched. But I thought I might as well give it a go.
The SysOps certificate focusses a lot on configuration and monitoring. You learn a lot about load balancers, autoscaling policies, CloudFormation and CloudWatch. And yes, all that indepth knowledge about VPCs and hybrid-cloud set-ups is applicable here too. A typical exam question will present a scenario where something has gone wrong, and you have to pick the best option to fix it. For example, someone can’t SSH into an EC2 instance because something is wrong with the security group. Or someone in a child account of a parent organisation can’t access something in another child account. Yet again I went to Stephane Maarek’s course, which was again excellent (https://www.udemy.com/course/ultimate-aws-certified-sysops-administrator-associate/). And Jon Bonzo again provided the practice exams (https://www.udemy.com/course/aws-certified-sysops-administrator-associate-practice-exams-soa-c01/).
I sat the SysOps exam in June 2022. One thing that caused a little trepidation was that this exam includes “exam labs” – these are practical exercises carried out in the AWS console. It was hard to prepare for these because I could not find any practice labs on-line, and so I was going in cold. However, it turned out that the labs were well defined with clear steps on what was required. Even the ones where I had never really looked at the service before, I was able to find it in the console and figure out what I needed to do. I was asked to:
Create a backup plan for an EFS system with two types of retention policy
Update a CloudFormation stack to fiddle with some EC2 settings, roles, route tables etc
Create an S3 static website and configure some Route 53 failover policies
The second of these caused me the most difficulty – I hadn’t anticipated actually having to write a CloudFormation template – they provided one which I needed to edit and it took me a while to figure out how to actually do this. Turns out that you need to save a new version of the template locally and then re-upload it.
I passed the SysOps exam with a more modest mark than for the other certifications, and I definitely breathed a sigh of relief. I am now definitely taking a breather – perhaps in a few months I might take a look at some of the specialist certifications (maybe Data Analytics?) but for the moment I’m going to get back to some of my other neglected hobbies (I like to draw, and play the piano, and one day I’ll maybe finish my epic fantasy trilogy).
The key take-aways from my experience are:
The associate level certifications require you to acquire knowledge that is directly applicable in the day-to-day life of a developer or systems administrator.
I was initially concerned that the courses would be part of a propaganda machine from AWS, encouraging us to spend ever larger amounts on AWS services. I found this to not be the case at all. Quite a large part of the material teaches us how to save costs, and how to incorporate our existing on-premises infrastructure with AWS, rather than replacing it entirely.
Sitting an exam in your own home is definitely preferable than travelling to a test centre – you get far more flexibility over when you can take the exam. However, not everyone will have a suitable place at home to take the exam, particularly if you share your home with other people, or you do not have a suitable table to work at.
Studying for these certifications will require a significant time commitment. The online courses run for 20-30 hours or more, assuming you never pause the videos to take notes, or repeat a section. And that is before you take time to revise or do practice exams.
Definitely the most valuable tool for preparing for the exams is by completing as many practice exams as you can find. The best ones include detailed explanations about why a particular answer is correct and the others are wrong.
Also note that these certifications have an expiry date – typically 3 years – and also the courses are refreshed periodically. For example, the Solutions Architect Associate is being refreshed at the end of August and Solutions Architect Professional is being refreshed in November.
Last Friday we had a dev forum on parsing data that came up as some devs had pressing question on Regex. Dan provided us with a rather nice and detailed overview of different ways to parse data. Often we encounter situations where an input or a data file needs to be parsed so our code can make some sensible use of it.
After the presentation, we looked at some code using the parboiled library with Scala. A simple example of checking if a sequence of various types of brackets has matching open and closing ones in the correct positions was given. For example the sequence ({[<<>>]}) would be considered valid, while the sequence ((({(>>]) would be invalid.
First we define the set of classes that describes the parsed structure:
object BracketParser {
sealed trait Brackets
case class RoundBrackets(content: Brackets)
extends Brackets
case class SquareBrackets(content: Brackets)
extends Brackets
case class AngleBrackets(content: Brackets)
extends Brackets
case class CurlyBrackets(content: Brackets)
extends Brackets
case object Empty extends Brackets
}
Next, we define the matching rules that parboiled uses:
package com.sixtysevenbricks.examples.parboiled
import com.sixtysevenbricks.examples.parboiled.BracketParser._
import org.parboiled.scala._
class BracketParser extends Parser {
/**
* The input should consist of a bracketed expression
* followed by the special "end of input" marker
*/
def input: Rule1[Brackets] = rule {
bracketedExpression ~ EOI
}
/**
* A bracketed expression can be roundBrackets,
* or squareBrackets, or... or the special empty
* expression (which occurs in the middle). Note that
* because "empty" will always match, it must be listed
* last
*/
def bracketedExpression: Rule1[Brackets] = rule {
roundBrackets | squareBrackets |
angleBrackets | curlyBrackets | empty
}
/**
* The empty rule matches an EMPTY expression
* (which will always succeed) and pushes the Empty
* case object onto the stack
*/
def empty: Rule1[Brackets] = rule {
EMPTY ~> (_ => Empty)
}
/**
* The roundBrackets rule matches a bracketed
* expression surrounded by parentheses. If it
* succeeds, it pushes a RoundBrackets object
* onto the stack, containing the content inside
* the brackets
*/
def roundBrackets: Rule1[Brackets] = rule {
"(" ~ bracketedExpression ~ ")" ~~>
(content => RoundBrackets(content))
}
// Remaining matchers
def squareBrackets: Rule1[Brackets] = rule {
"[" ~ bracketedExpression ~ "]" ~~>
(content => SquareBrackets(content))
}
def angleBrackets: Rule1[Brackets] = rule {
"<" ~ bracketedExpression ~ ">" ~~>
(content => AngleBrackets(content))
}
def curlyBrackets: Rule1[Brackets] = rule {
"{" ~ bracketedExpression ~ "}" ~~>
(content => CurlyBrackets(content))
}
/**
* The main entrypoint for parsing.
* @param expression
* @return
*/
def parseExpression(expression: String):
ParsingResult[Brackets] = {
ReportingParseRunner(input).run(expression)
}
}
While this example requires a lot more code to be written than a regex, parsers are more powerful and adaptable. Parboiled seems to be an excellent library with a rather nice syntax for defining them.
To summarize, regexes are very useful, but so are parsers. Start with a regex (or better yet, a pre-existing library that specifically parses your data structure) and if it gets too complex to deal with, consider writing a custom parser.
This is a slightly abridged version of a painful experience I had recently when trying to book a Covid vaccination for my 5-year-old daughter, and some musing about what went wrong (spoiler: IT systems). It’s absolutely not intended as a criticism of anyone involved in the process. All descriptions of the automated menu process describe how it was working today.
Recently we had an interesting dev forum on Git workflows. Git is the de facto source control tool of choice for software development. Powerful and flexible, teams have a wide range of choices to make when deciding exactly how to make use of it. This discussion originally stemmed from a Changelog podcast titled “Git your reset on” based on the blog post “Git Organized” by Annie Sexton.
To briefly summarise the above, if we imagine a situation where a merge to main leads to a production deployment and then an issue is found in production, how do we roll back? We look in the git history, find the commit that introduced the bug, revert it and then redeploy to production. But oh no! This revert changed a number of source files beyond the scope of the bug and has ended up introducing a new bug.
The proposed solution to this is to ensure a sensible, clean history of commits is used within a branch. Annie Sexton suggests using a feature branch where you commit regularly with useless messages like WIP until you are ready to submit a pull request. You then run git reset origin/head to be presented with all the changes you have done and how this differs from main, you then progressively add files and make commits with sensible messages to build up a more coherent change.
This approach has a number of advantages we discussed:
It provides a neat history of compartmentalised changes
Reviewers can then follow a structured story of commits about how the developer arrived at their solution
Irrelevant changes are excluded
Ensure that all of the included changes are relevant only to the task at hand
Disadvantages of this approach may include:
Bad approaches that were tried and abandoned are not in the history
Changes aren’t going to always compartmentalise neatly into specific changes of files meaning we would need to commit specific changes within a file, some tools do a bad job supporting this use case
It turns out that a lot of developers at 67 Bricks use a form of history rewriting when developing code, but no one used the specific approach proposed above. git commit–amend is a very useful command to tweak the previous commit. Some (including myself) use git rebase -i as a way of rebuilding the commit history, though this has a limitation in cases where you may want to split a commit up. Finally, others create new branches and build up clean commits on the new branch.
Is force pushing a force for good?
This question really split the developers, some see using git push --force as an evil that indicates you’re using git wrongly and should only be used as a last resort. Others really like the idea of force pushing, but only for branches you’ve been developing on and have yet to create a merge request for.
Squashing?
A workflow some developers have seen before involves using the --squash flag when merging into main. This can create a nice history where each commit neatly maps to a single ticket but the general view was this caused the loss of helpful information from the git history.
Should the software be valid at every commit?
Some argued that this is a sensible thing to strive for, having confidence that you can revert back to any commit and the software will work is a nice place to be at. However, others criticised this as tricky to achieve in practice. Ideally the tests would all be valid and pass too, but this goes against how some developers work; they create a failing test to show the problem or new feature, commit it and then build out code to make the test green. Others claim that tests should change in the same commit as code changes to make it obvious these changes belong together.
Tools used by Developers
At 67 bricks, we try to avoid specifying which precise tool a developer should use for their craft. Different developers prefer different approaches when it comes to using git, some are more comfortable with their IDEs plugin (e.g. IntelliJ has good git integration which can add specific lines to commits) while others may prefer using the command line. Here’s a list of tools we’ve used when dealing with git:
When investigating slow XQuery or XSLT queries in MarkLogic, one of the tools it provides is a query profiler. In this post I’ll explain how to make use of the profiler and how to interpret the results.
There are 3 ways you can make use of the profiler:
use the MarkLogic QConsole;
use an IDE that supports the profiler like IntelliJ with the XQuery and XSLT plugin;
use the MarkLogic profiler API.
Using the QConsole
In the MarkLogic QConsole you can enable profiling by clicking on the Profile tab next to the Results tab and pressing the Run button. This will display a table with the profiling results. The profile can be saved by clicking on the download button on the right.
The profile result table contains the following information:
Module:Line No.: Col No. – This is where the expression being profiled starts;
Count – This is the number of times the expression was evaluated;
Shallow %/Shallow ms – This is how long the expression took to run on its own across all Count times it was evaluated;
Deep %/Deep ms – This is how long the expression took to run in addition to the time subexpessions took to evaluate;
Expression – This is the string representation of the query expression being evaluated.
NOTE: Here, ms is microseconds not milliseconds.
If you want to do further processing on the downloaded profile:report XML, you can load that XML by using:
let $data := xdmp:filesystem-file("C:\profiling\profile.xml")
let $profile := xdmp:unquote($data)/prof:report
Analysing Profile Results
Sorting by shallow time is useful for identifying the expressions that take a long time to evaluate. This can identify places where you should modify the query or add indices.
The count column is also useful. It can indicate places where you have nested loops that result in quadratic time queries.
When making optimizations, it can be tricky to know if a change results in a speed up of the query or is not significant, but shows up in the normal time variation when running a query multiple times. To handle this, I like to use a spreadsheet and measure the average (mean) time and standard deviation over 5 or 10 runs.
This can also be useful when varying the number of items being processed (e.g. documents) in order to identify if the query scales with that item, and whether the scaling is linear, quadratic, or some other curve. For this, you can use line graphs to visualise the performance and linear or quadratic regression formulae to check what shape the graph is.
The stock chart graph is useful for comparing the variation between runs. Here, the mininum and maximum times form the extents (low, high) of the chart, and the mean +/- one standard deviation form the inner bar (open, close) of the chart.
Using the Profiler API
Using the profiler API you can use the following to collect the profile data from a query expression:
let $_ := prof:enable(xdmp:request())
(: code to profile, e.g. -- let $_ := local:test() :)
let $_ := prof:disable(xdmp:request())
let $profile := prof:report(xdmp:request())
NOTE: If you are running this from an XQuery 1.0 query instead of a 1.0-ml query then you need to declare the prof namespace:
You can then either save the profile to a file, e.g.:
let $_ := xdmp:save("C:\profiling\profile.xml", $profile)
or process the resulting profile:report XML in the XQuery script.
Alternatively you can use one of the prof:eval or prof:xslt-eval to evaluate an in memory query, or prof:invoke or prof:xslt-invoke to evaluate a module file. These return the profile data as the first item and the result as the remaining items, so you can use the following:
let $ret := prof:eval("for $x in 1 to 10 return $x")
let $profile := $ret[1]
let $results := $ret[position() != 1]
With the profile report XML, you can then process it as you need. For example, to create a CSV version of the QConsole profile table you can use the following query:
declare function local:to-seconds($value) {
($value cast as xs:dayTimeDuration) div xs:dayTimeDuration("PT1S")
};
let $overall-elapsed := local:to-seconds($profile/prof:metadata/prof:overall-elapsed)
for $expression in $profile/prof:histogram/prof:expression
let $source := $expression/prof:expr-source/string()
let $uri := string(($expression/prof:uri/text(), "main")[1])
let $line := $expression/prof:line cast as xs:integer
let $column := ($expression/prof:column cast as xs:integer) + 1
let $count := $expression/prof:count cast as xs:integer
let $shallow-time := local:to-seconds($expression/prof:shallow-time)
let $deep-time := local:to-seconds($expression/prof:deep-time)
order by $shallow-time descending
return
string-join((
$uri, $line, $column, $count,
$shallow-time, ($shallow-time div $overall-elapsed) * 100,
$deep-time, ($deep-time div $overall-elapsed) * 100,
$source
) ! string(.), ",")
NOTE: This does not handle escaping of commas in the $source string.
I thought I’d pen a short blog post on a question I frequently find myself asking.
You’re right, but are you relevant?
Me
As software developers, it’s all too easy to want to select the new hot technologies available to us. Building a simple web app is great, but building a distributed web-app based on an auto-scaling cluster making use of CQRS and an SPA front-end written in the latest JavaScript hotness is just more interesting. Software development is often about finding simple solutions to complex problems, allowing us to minimize complexity.
You’re right, distributed microservices will allow you to deploy separate parts of your app independently, but is that relevant to a back-office system which only needs to be available 9-5?
You’re right, CQRS will allow you to better scale the database to handle a tremendous number of queries in parallel, but is that relevant when we only expect 100 users a day?
You’re right, that new Javascript SPA framework will let you create really compelling, interactive applications, but is that relevant to a basic CRUD app?
Lots of modern technology can do amazing things and there are always compelling reasons to choose technology x, but are those reasons relevant to the problem at hand? If you spend a lot of time up front designing systems with tough-to-implement technologies and approaches which aren’t needed; a lot of development effort would have been needlessly spent adding all kinds of complexity which wasn’t needed. Worse, we could have added lots of complexity that then resists change, preventing us from adapting the system in the direction our users require.
At 67 Bricks, we encourage teams to start with something simple and then iterate upon it, adding complexity only when it is justified. Software systems can be designed to embrace change. An idea that’s the subject of one of my favourite books Building Evolutionary Architectures.
So next time you find yourself architecting a big complex system with lots of cutting edge technologies that allow for all kinds of “-ilities” to be achieved. Be sure to stop and ask yourself. “I’m right, but am I relevant?”
At 67 Bricks, we are big proponents of functional programming. We believe that projects which use it are easier to write, understand and maintain. Scala is one of the most common languages we make use of and we see more object oriented languages like C# are often written with a functional perspective.
This isn’t to say that functional languages are inherently better than any other paradigms. Like any language, it’s perfectly possible to use it poorly and produce something unmaintainable and unreadable.
Immutable First
At first glance immutable programming would be a challenging limitation. Not being able to update the value of a variable is restrictive but that very restriction is what makes functional code easier to understand. Personally I found this to be one of the hardest concepts to wrap my head around when I first started functional programming. How can I write code if I can’t change the value of variables?
In practice, reading code was made much easier as once a value was assigned, it never changed, no matter how long the function was or what was done with the value. No more trying to keep track in my head how a long method changes a specific variable and all the ways it may not thanks to various control flows.
For example, when we pass a list into a method, we know that the reference to the list won’t be able to change, but the values within the list could. We would hope that the function was named something sensible, perhaps with some documentation that makes it clear what it will do to our list but we can never be too sure. The only way to know exactly what is happening is to dive into that method and check for ourselves which then adds to the cognitive load of understanding the code. With a more functional programming language, we know that our list cannot be changed because it is an immutable data structure with an immutable reference to it.
High Level Constructs
Functional code can often be more readable than object oriented code thanks to the various higher level functions and constructs like pattern matching. Naturally readability of code is very dependent on the programmer; it’s easy to make unreadable code in any language, but in the right hands these higher level constructs make the intended logic easier to understand and change. For example, here are 2 examples of code using regular expressions in Scala and C#:
def getFriendlyTime(string time): String = {
val timestampRegex = "([0-9]{2}):([0-9]{2}):([0-9]{2}).([0-9]{3})".r
time match {
case timestampRegex(hour, minutes, _, _) => s"It's $minutes minutes after $hour"
case _ => "We don't know"
}
}
public static String GetFriendlyTime(String time) {
var timestampRegex = new Regex("([0-9]{2}):([0-9]{2}):([0-9]{2}).([0-9]{3})");
var match = timestampRegex.Match(time);
if (match == null) {
return "We don't know";
} else {
var hours = match.Groups[2].Value;
var minutes = match.Groups[1].Value;
return $"It's {minutes} minutes after {hour}";
}
}
I would argue that the pattern matching of Scala really helps to create clear, concise code. As time goes on features from functional languages like pattern matching keep appearing in less functional ones like C#. A more Java based example would be the streams library, inspired by approaches found in functional programming.
This isn’t always the case, there are some situations where say a simple for loop is easier to understand than a complex fold operation. Luckily, Scala is a hybrid language, providing access to object oriented and procedural styles of programming that can be used when the situation calls for it. This flexibility helps programmers pick the style that best suits the problem at hand to make understandable and maintainable codebases.
Pure Functions and Composition
Pure functions are easier to test than impure functions. If it’s simply a case of calling a method with some arguments and always getting back the same answer, tests are going to be reliable and repeatable. If a method is part of a class which maintains lots of complex internal state, then testing is going to be unavoidably more complex and fragile. Worse is when the class requires lots of dependencies to be passed into it, these may need to be mocked or stubbed which can then lead to even more fragile tests.
Scala and other functional languages encourage developers to write small pure functions and then compose them together in larger more complex functions. This helps to minimise the amount of internal state we make use of and makes automated testing that much easier. With side effect causing code pushed to the edges (such as database access, client code to call other services etc.), it’s much easier to change how they are implemented (say if we wanted to change the type of database or change how a service call is made) making evolution of the code easier.
For example, take some possible Play controller code:
def updateUsername(id: int, name: string) = action {
val someUser = userRepo.get(id)
someUser match {
case Some(user) =>
user.updateName(name) match {
case Some(updatedUser) =>
userRepo.save(updatedUser)
bus.emit(updatedUser.events)
Ok()
None => BadRequest()
case None => NotFound()
}
def updateEmail(id: int, email: string) = action {
val someUser = userRepo.get(id)
someUser match {
case Some(user) =>
user.updateEmail(email) match {
case Some(updatedUser) =>
userRepo.save(updatedUser)
bus.emit(updatedUser.events)
Ok()
case None => BadRequest()
case None => NotFound()
}
Using composition, the common elements can be extracted and we can make a more dense method by removing duplication.
def updateUsername(id: int, name: string) = action {
updateEntityAndSave(userRepo)(id)(_.updateName(name))
}
def updateEmail(id: int, email: string) = action {
updateEntityAndSave(userRepo)(id)(_.updateEmail(email))
}
}
private def updateEntityAndSave(repo: Repo[T])(id: int)(f: T => Option[T]): Result = {
repo.get(id) match {
case Some(entity) =>
f(entity) match {
case Some(updatedEntity) =>
repo.save(updatedEntity)
bus.emit(updatedEntity.events)
Ok()
None => BadRequest()
case None => NotFound()
}
None Not Null
Dubbed the billion-dollar mistake by Tony Hoare, nulls can be a source of great nuisance for programmers. Null Pointer Exceptions are all too often encountered and confusion reigns over whether null is a valid value or not. In some situations a null value may never happen and need not be worried about while in others it’s a perfectly valid value that has to be considered. In many OOP languages, there is no way of knowing if an object we get back from a method can be null or not without either jumping into said method or relying on documentation that often drifts or does not exist.
Functional languages avoid these problems simply by not having null (often Unit is used to represent a method that doesn’t return anything). In situations where we may want it, Scala provides the helpful Option type. This makes it explicit to the reader that you call this method, you will get back Some value or None. Even C# is now introducing features like Nullable Reference Types to help reduce the possible harm of null.
Scala also goes a step further, providing an Either construct which can contain a success (Right) of failure (Left) value. These can be chained together to using a railway styles of programming. This chaining approach can lead us to have an easily readable description of what’s happening and push all our error handling to the end, rather than sprinkle it among the code.
Using Option can also improve readability when interacting with Java code. For example, a method returning null can be pumped through an Option and combined with a match statement to lead to a neater result.
Option(someNullReturningMethod()) match {
case Some(result) =>
// do something
case None =>
// method returned null. Bad method!
}
Conclusions
There are many reasons to prefer functional approaches to programming. Even in less functionally orientated languages I have found myself reaching for functional constructs to arrange my code. I think it’s something all software developers should try learning and applying in their code.
Naturally, not every developer enjoys FP, it is not a silver bullet that will overcome all our challenges. Even within 67 Bricks we have differing opinions on which parts of functional programming are useful and which are not (scala implicits can be quite divisive). It’s ultimately just another tool in our expansive toolkit that helps us to craft correct, readable, flexible and functioning software.