Note, this post is based on a dev forum put together by Chris.
Full-text search is a common feature of systems 67 Bricks build. We want to make it easy for users to find relevant information quickly often through a faceted search function. Understanding user needs and building a top notch user experience is vital. When building faceted search, we generally use either ElasticSearch (or AWS’s OpenSearch) or MarkLogic. Both databases offer very similar feature sets when it comes to search, though one is more targetted towards JSON based documents and the other, XML.
Search can seem magical at first glance and do some amazing things but this can lead to situations where customers (and UX/UI designers) assume the search mecahnism can do more than it can. We frequently find a disconnect between what is desired and what is feasable with search systems.
There are 2 main categories of problems we often see are:
- Customers / Designers asking for things that could be done, but often come with nasty performance implications
- Features that seem reasonable to ask for at first glance, but once dug into reveal logical problems that make developing the feature near impossible
Faceted Search
Faceted search systems are some of the most common systems we build at 67 Bricks. The user experience typicallly starts with a search box that they enter a number of terms into, hit enter and then be presented with a list of results in some kind of relevancy order. Often there is a count of results displayed alongside a pagination mechanism to iterate through the results (e.g. showing results 1-10 of 12,464). We also show facets, counts for how many results fit into different buckets. All this is handled in a single query that often takes less than 100ms which seems miraculous. Of course, this isn’t magic, full-text search systems use a variety of clever indexes to make searching and computing the facet counts quick.
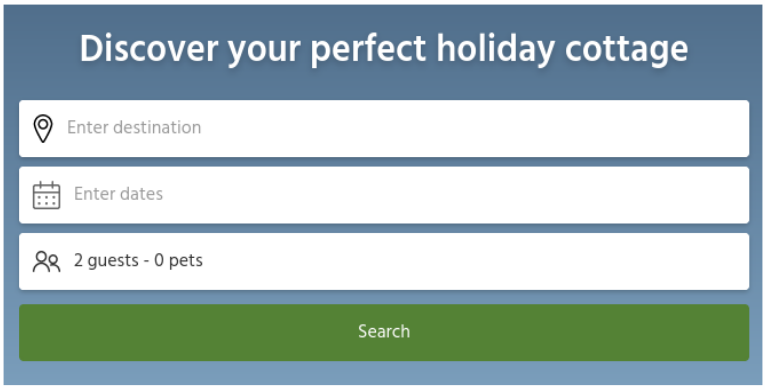
Lets make a search system for a hypothetical website cottagesearch.com. Our first screen will present the user with some options to select a location, the date range they want to stay and how many guests are coming. We perform the search and show the matching results. How should we display the results and more importantly, how do we show the facets?

Let’s say we did a search for 2 bedroom cottages. We’ve seen wireframes for a number of occassions where the facet count for all bedroom numbers are displayed. So users see the number of results applicable to each bedroom count they would get if they didn’t limit the search to just 2 bedrooms (i.e. there aren’t that many 2 bed options, but look at how many 3 bed options are available). At first glance, this seems like a sensible design, but fundmanetally breaks how search systems work with faceting, they will return counts, but only for the search just done.
We could get around this by doing 2 searches, 1 limited by bedrooms and one that does not to retrieve the facet counts. This may seem like a sensible idea when we have 1 facet, but what do we do when we have more? Do we need to do multiple searches, effectively making an N+1 problem? How to we display numbers? Should the counts for the location facet include the limit of bedrooms or not? As soon as we start exploring additional situations we start to see the challenges the original design presents.
This gets harder when we consider non-exclusionary facets. Let’s say our cottage search system lets you filter by particular features, such as a wood burner, hot tub or dishwasher. Now, if we show counts of non-selected facets, what do these numbers represent? Do they include results that already include the selected facet or not? Here, the logic starts to break down and becomes ever more confusing to the end user and difficult to implement for the developer.

Other Complex Facet Situations
A common question we need to ask with non-exclusionary facets: Is it an AND or an OR search? The answer is very domain dependant, but either way we suggest steering away from facets counts in these situations.
Date ranges provide an interesting problem, some sites will purposefully search outside of the selected range so as to provide results near the selected date range. This may be a useful or annoying depending on what the user expects and is trying to achieve. Some users would want exact matches and would have no interest in results that do not meet the selected date range.
Ordering facets is also a questions that may be overlooked. Do you order lexographically or do you order by descending number of matches? What about names, year ranges or numeric values? Again, a lot of what users expect and would want comes down to the domain being dealt with and the needs of the users.
When users select a new facet, what should the UI do? Should the search immediately rerun and the results and facets update or should there be a manual refresh button the user has to select before the search is updated? An immediate refresh would be slower, but let users narrow down carefully, while a manual update would reduce the number of searches done, but then users may be able to select a number of facets in such a way that no results would be returned.
Hierarchies can also prove tricky. We often see taxonomies being used to inform facets, say subjects with sub categories. How should these be displayed? Again there are many solutions to pick from with different sets of trade-offs.
Advanced Search
Advanced search can often be a bit like a peacocks tail – something that looks impressive, but doesn’t contribute a fair share of value based on how much effort it takes to develop. A lot of designers and product owners love the idea of it but in practice, it can end up being somewhat confusing to use and many end users end up avoiding it.
Boolean builders exist in many systems where the designer of advanced search will insist on allowing users to build up some complex search with lots of boolean AND/OR options, but displaying this to users in a way they can understand is challenging. If a user builds a boolean search such as: GDP AND Argentina OR Brazil do we treat it as (GDP AND Argentina) OR Brazil or should it be interpreted as GDP AND (Argentina OR Brazil). We could include brackets in the builder, but this just further complicates the UI.
We frequently get bugs and feedback on advanced search, some of this feedback can amount to different users having contradictory opinions on how it should work. We would ask product owners to carefully consider “How many people will use it?” Google has a well build UI for advanced search that does away with the challenges of boolean logic by having separate fields for ANDs ORs and NOTs.
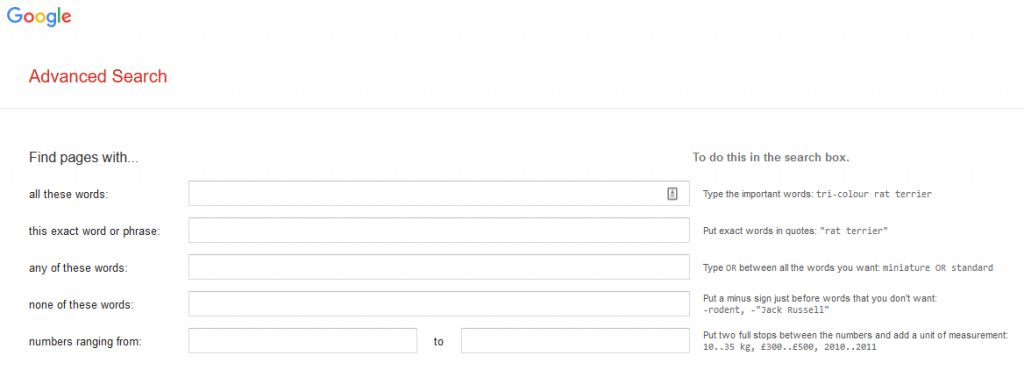
An advanced search facility can introduce additional complexity when combined with facets. If an advances search lets you select some facets before completing the search, does this form part of the string in the search box? We have had mixed results with enabling power users to enter facets into search fields (e.g. bedrooms:3), but this can be tricky, some users can deal with it, but others may prefer a advanced search builder while others will rely on facets post search.
Summary
In conclusion, we have 3 main takeaways
- Search is much more complex than it first appears
- Facets are not magic, just because you can draw a nice wireframe doesn’t make it feasable to develop
- Advanced search can be tricky to get right and even then, only used by a minority of users
We’ve build many different types of search and have experimented with a number of approaches in the past and we offer some tried and tested principles:
- Make searches stateless – Don’t add complexity by trying to maintain state between facets changes, simply treat each change as a fresh search. That way URLs can act as a method of persistence and bookmarking common searches.
- Have facets only display counts for the current search and do not display counts for other facets once one has been selected within that category.
- Only use relevancy as the default ordering mechanism – You may be tempted to allow results to be ordered in different ways, such as published date, but this can cause problems with weakly matching, but recent results appearing first.
- Don’t build an advanced search unless you really need to and if you have to, use a Google style interface over a boolean query builder.
- Check that search is working as expected – Have domain experts check that searches are returning sensible results and look into using analytics to see if users are having a happy journey through the application (i.e. run a search and then find the right result within the first few hits).
- Beware of exhaustive search use cases – As many search mechanisms work on some score based on relevancy to the terms entered, having a search that guarantees a return of everything relevant can be tricky to define and to develop.